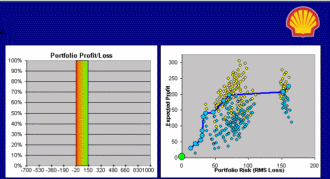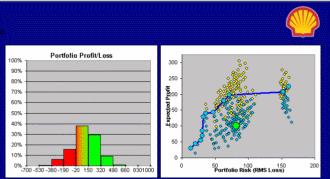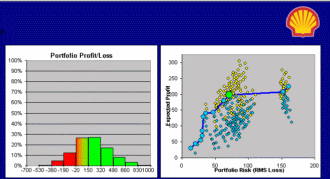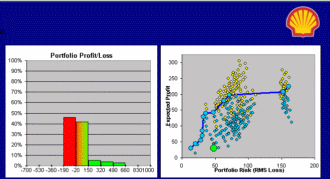
What Do You Want It to Be?
by Sam L. Savage

The Shmoo is a fictional character created in 1948 by cartoonist Al Capp for his Li’l Abner cartoon strip.
According to Shmoo - Wikipedia,
Shmoos are delicious to eat, and are eager to be eaten. If a human looks at one hungrily, it will happily immolate itself—either by jumping into a frying pan, after which they taste like chicken, or into a broiling pan, after which they taste like steak. When roasted they taste like pork, and when baked they taste like catfish. Raw, they taste like oysters on the half-shell.
They also produce eggs (neatly packaged), milk (bottled, grade-A), and butter—no churning required. Their pelts make perfect bootleather or house timbers, depending on how thick one slices them.
These famous mathematical Shmoos were developed hundreds of years ago. A brand new Shmoo is the Metalog, invented by Tom Keelin to mimic probability distributions. Its basis functions are related to the Logistic distribution, hence the name Metalog(isitic).
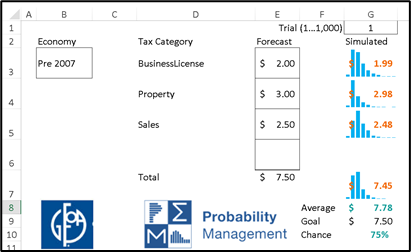
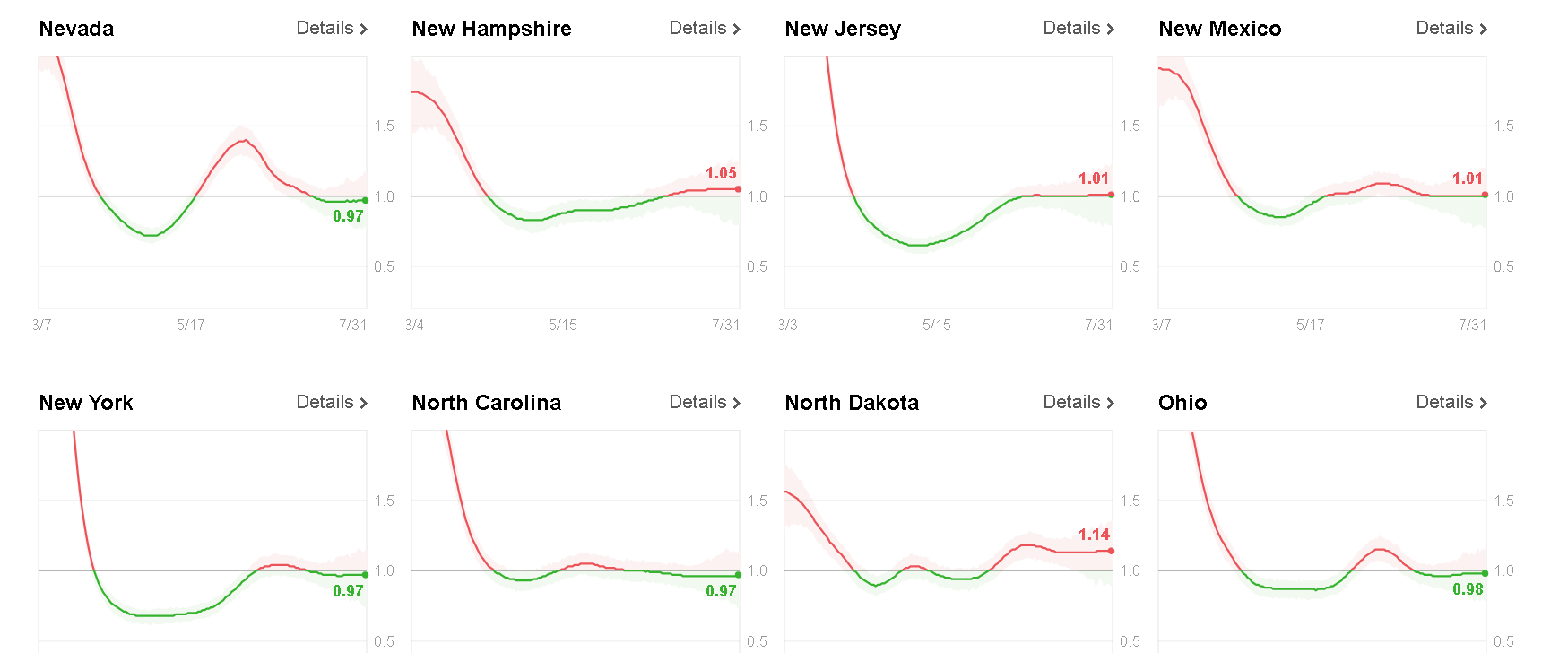
It has been five years since Tom first explained his elegant family of probability distributions to me, and today Metalogs play diverse and vital roles within the discipline of probability management, which is concerned with conveying uncertainty as data that obey both the laws of arithmetic and the laws of probability. I expect Metalogs to revolutionize the much larger field of statistics as well, but that will be more like turning an aircraft carrier compared to the patrol boat of probability management. Being small and maneuverable has given our organization the rare opportunity to help pioneer a real breakthrough.
The value of a revolutionary idea is not obvious, or it wouldn’t be revolutionary. My first reaction to Metalogs was, that’s very nice, but now I have one more distribution to remember along with the Erlang, Gaussian, Gompertz, Weibull, and all the other “Dead Statistician” distributions. The whole point of probability management is that the user doesn’t need to remember all this junk, and now I have something else to cram into my closet.
In retrospect I have rarely been so wrong. It took a while to figure out that I could actually put the Metalogs in the closet and then take the rest of the contents out to the curb for bulk trash pickup. But I’m getting ahead of myself. This is the first in a series of blogs on revelations about Metalogs, a subject which is growing fast. Some of my readers will want to know all about Metalogs and all of my readers will want to know something about Metalogs. But in the future, I believe that many of my 7.6 billion non-readers will know nothing about Metalogs, yet will be impacted by them nonetheless.
Tom has just created a concise 7-minute Flash Intro to Metalogs video that I highly recommend. If you don’t have seven minutes, it plays beautifully at 1.5 x, resulting in 4.66 minutes that might just change the way you think about statistics. Then stay tuned for my subsequent blogs that cover other important aspects of Metalogs.