The Generator Generator
by Sam L. Savage
Distribution Distribution
Decades ago, I discovered that few managers were benefiting from probabilistic analysis. Despite widely available simulation software such as @RISK and Crystal Ball, most people lacked the statistical training required to generate the appropriate distributions of inputs.
“But wait a minute,” I thought to myself. “The general public still uses light bulbs even though they don’t know how to generate the appropriate electrical current.” After some research I discovered that there is a power distribution network that carries current from those who know how to generate it to those who just want to use it.
So why not create a Distribution Distribution network, to carry probability distributions from the people who know how to generate them (statisticians, econometricians, engineers, etc.) to anyone facing uncertainty?
Great idea, but it took me a while to figure out the best way to distribute distributions. Eventually I arrived at the SIPs and SLURPs of probability management, which represent distributions as vectors of realizations and metadata which support addition, multiplication, and any other algebraic calculation, while capturing any possible statistical relationship between variables. This concept even works with the data set invented by Alberto Cairo, made up of SIPs I call Dino and saur [i].

A Scatter Plot of Alberto Cairo’s Dino and saur
Once Excel fixed the Data Table, it became possible to process SIPs in the native spreadsheet, which greatly accelerated adoption [ii]. SIPs and SLURPs have been a simple, robust solution, although they do require a good deal of storage.
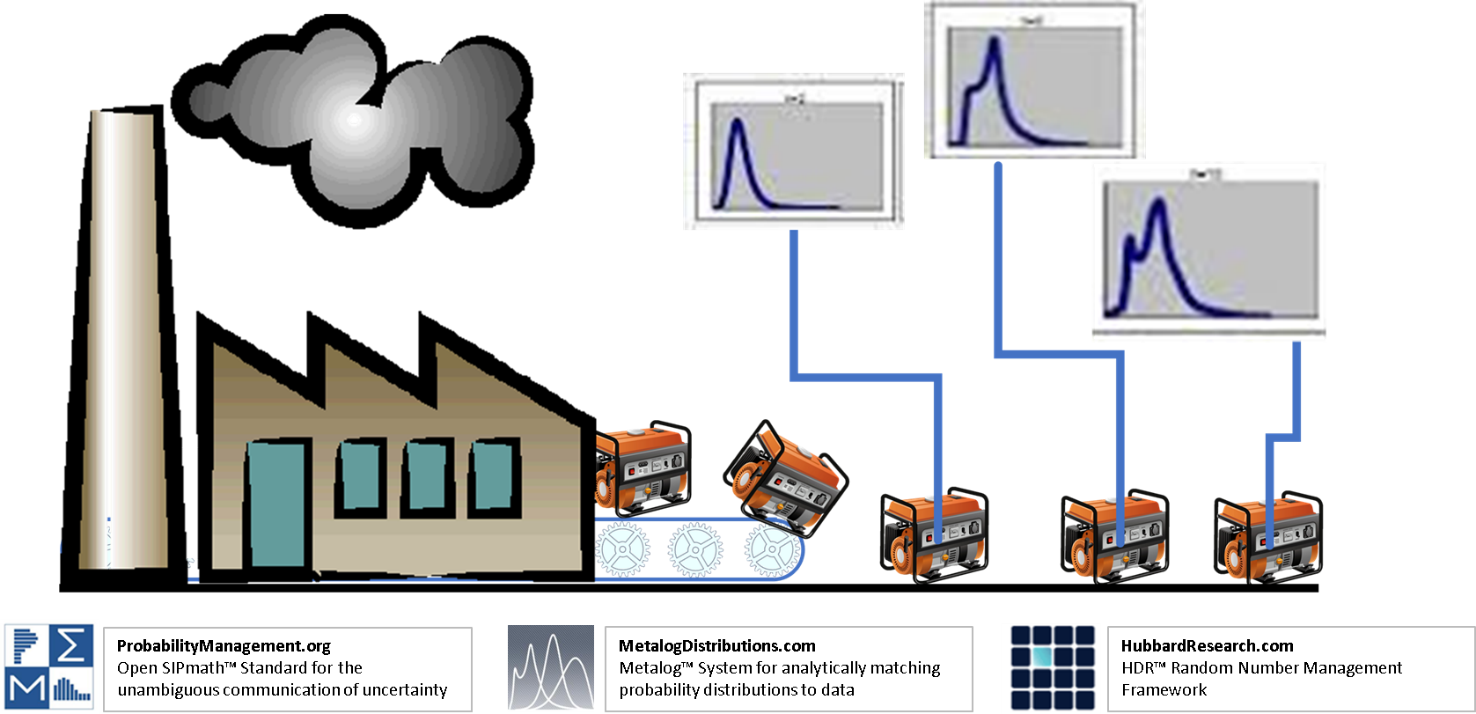
Before I thought of SIPs, I had thought of and abandoned an idea involving snippets of code which would generate a random number generator when they arrived on a client computer. I called this approach the Generator Generator (well, that was for short—the full name was the Distribution Distribution Generator Generator). The advantage of such a system is that the storage requirements would be tiny compared to SIPs, and you could run as many trials as you liked. It might not be possible to capture the interrelationships of Dino and saur, but at least some forms of correlations could be preserved.
The SIPmath/Metalog/HDR Integration
Recent breakthroughs from two comrades-in-arms in the War on Averages have made the Generator Generator a reality and allowed it to be incorporated into the SIPMath Standard. One key ingredient is Tom Keelin’s amazingly general Metalog System for analytically modeling virtually any continuous probability distribution with one formula.
Another is Doug Hubbard’s latest Random Number Management Framework, which in effect can dole out independent uniform random numbers like IP addresses while maintaining the auditability required by probability management. This guarantees that when global variables such as GDP are simulated in different divisions of an organization, they will use same random number seed. On the other hand, when simulating local variables, such as the uncertain cost per foot of several different paving projects, different seeds will be guaranteed. This allows individual simulations to be later aggregated to roll up enterprise risk. Doug’s latest generator has been tested thoroughly using the rigorous dieharder tests [iii].
At ProbabilityManagement.org, we have wrapped these two advances into the Open SIPmath Standard for creating libraries of virtual SIPs, which will take up a tiny fraction of the storage of current SIP libraries. We hope to release the tools to create such libraries at our Annual Meeting in San Jose on March 26 and 27. Tom, Doug, and I will be presenting there, along with an all-star cast of other speakers. I hope we see you there.
© Copyright 2019, Sam L. Savage
[i] http://www.thefunctionalart.com/2016/08/download-datasaurus-never-trust-summary.html
[ii] Savage, S.L. Distribution Processing and the Arithmetic of Uncertainty, Analytics Magazine, November/December 2012.
[iii] https://webhome.phy.duke.edu/~rgb/General/dieharder.php